MySQL Full-text Search - P3
Giới thiệu
Tiếp theo phần trước, thì phần này ta sẽ tìm hiểu về cơ chế đánh giá độ phù hợp (relevance) của MySQL và cơ chế Indexing.
1.Kiến trúc tổng quát
Trước tiên, ta hãy xem qua kiến trúc tổng thể của full text search, trong đó bao gồm MySQL, tuy nhiên tùy thuộc vào đặc điểm của mỗi search engine mà nó sẽ khác nhau (ví dụ như MySQL không có stemmer vì vậy khi search 1 từ số nhiều bằng keyword số ít sẽ không ra).
Đầu tiên một tài liệu đầu vào sẽ trải qua một số quá trình xử lý như tokenizing, stemming, và được lọc bỏ các từ trong stopword list. Sau đó các token trải quá quá trình indexing và ghi xuống file index.
Quá trình đầu tiên, tokenizer sẽ băm nhỏ tài liệu đầu vào thành những đơn vị tài liệu nhỏ nhất (tùy theo ngôn ngữ nó có thể là từ đối với tiếng Anh, Việt hay là ký tự đối với các thứ tiếng CJK). Về mặt kỹ thuật thì từ (word) cách được phân cách bởi khoảng trắng, còn đối với các ngôn ngữ Trung-Nhật-Hàn thì mình không rõ, thì họ có thể viết liền kề nhau không có khoảng trắng).
Sau đó tới quá trình stemming, stemmer có nhiệm vụ đưa các biến thể của một từ về dạng gốc của nó. Ví dụ như trong tiếng Anh các từ jump, jumps, jumped, jumping đều có gốc chung là chữ jump.
Và sau đó, chuỗi đầu vào sẽ được lọc bỏ các stopword, tức là bỏ đi các từ không có ý nghĩa trong việc chọn ra tài liệu nào phù hợp với keyword của người dùng nhập vào. Ví dụ như mặc định trong MySQL các từ như là hello, welcome, were, it, us v.v sẽ bị lọc bỏ (xem danh sách đầy đủ ở đây).
2.Index là gì?
Theo như Wikipedia định nghĩa, Index là một loại cấu trúc dữ liệu giúp cải thiện tốc độ truy xuất dữ liệu, nhưng bù lại sẽ làm tăng thời gian ghi dữ liệu và tốn nhiều không gian lưu trữ hơn. Thật ra khái niệm index này có thể bắt gặp ngoài đời thực, đằng sau những quyển sách, đó là một danh sách cho phép người đọc dễ dàng tra cứu từ nào xuất hiện ở trang nào. Ta có thể xem một trang index trong quyển sách Lucence in Action.

Thường thì cấu trúc index được dùng phổ biến trong các search engine là Inverted Index.
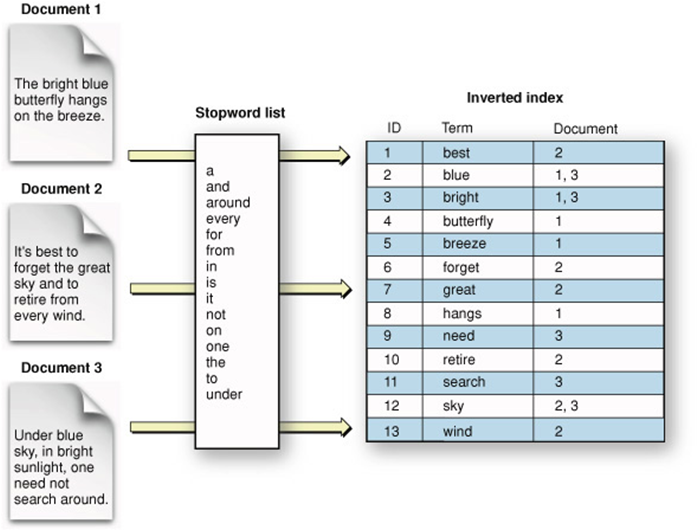
Cũng gần giống với các cuốn sách, Inverted Index sẽ lưu trữ Từ nào xuất hiện trong document nào. Vì vậy việc tìm kiếm thông qua Index rất nhanh so với việc scan toàn bộ table để tìm ra tài liệu có chứa từ đó. (giống như việc bạn truy xuất các phần tử của một array qua index thay vì lặp từng phần tử vậy).
3.Relevance Rank
Như bạn đã đọc ở phần 2, thì NATURAL LANGUAGE MODE mặc định được sort bởi độ phù hợp (relavance). Điểm cho mức độ phù hợp được gọi là weight, được tính theo công thức sau:
w = (log(dtf)+1)/sumdtf * U/(1+0.0115*U) * log((N-nf)/nf)
Cụ thể thì chúng ta có thể tìm hiểu thêm ở bài Viết MySQL Internal Algorithm. Tuy nhiên về mặt nghĩa thì có thể hiểu nôm na như sau:
Nếu một từ khóa xuất hiện nhiều lần trong một tài liệu, thì điểm weight của từ khóa ấy tăng lên. Nếu như từ khóa ấy xuất hiện trong nhiều tài liệu khác thì số điểm bị giảm đi.
Như vậy thì một từ không xuất hiện trong bất kỳ tài liệu nào, hoặc từ khóa xuất hiện trong hầu hết các tài liệu thì đều có điểm thấp, và không thể tìm ra được. Ta lấy ví dụ về từ khóa MySQL trong dữ liệu giới thiệu ở phần 2.
Ta có thể hiểu rõ hơn việc này bằng cách xem số điểm mà MySQL được chấm trong Index bằng công cụ myisam_ftdump trong mysql\bin (c có nghĩa là count và 1 là chỉ số của full text index(title,body), còn 0 là index của id)
Ta có thể thấy từ khóa MySQL được chấm điểm âm (bé hơn 0!). Bởi vì từ khóa này xuất hiện trong tất cả các records hiện tại mà ta dùng để test. Nếu thử với các từ khóa khác thì sẽ có ít nhất một kết quả trả về. (Lưu ý là mặc định chúng ta tìm bằng NATURAL LANGUAGE MODE, tuy nhiên nếu chuyển sang BOOLEAN MODE thì vẫn có kết quả trả về cho từ khóa MySQL vì trong BOOLEAN MODE thì mặc định engine chỉ tìm xem có hay không từ khóa đó (1-0)).
Sau đây, chúng ta sẽ quay trở lại BOOLEAN MODE một chút để tìm hiểu về weight trong chế độ này.
Như chúng ta thấy, kết quả trả về weigth chỉ mang giá trị 0 hoặc 1, tức là có xuất hiện hay không có xuất hiện. Tuy nhiên điểm số sẽ thay tăng hoặc giảm nếu như chúng ta sử dụng các wildcard đã giới thiệu trong phần 2.
Xem 2 ví dụ sau:
Điểm của record số 5 đã bé hơn một do có chứa từ YourSQL (wildcard ~ đánh dấu từ đó như từ YourSQL gây nhiễu, nên điểm thấp hơn).
Ngược lại nếu ta thêm toán tử > thì điểm số của record đó sẽ tăng lên:
Do ta dùng toán tử >YourSQL nên record số 5 được tăng điểm lên. Như vậy khi dùng các wildcard thì điểm số trong boolean mode không chỉ còn là 0 và 1 nữa. Cho nên ta phải sort kết quả trả về để được thứ tự mong muốn bằng cách sử dụng ORDER BY MATCH... AGAINST...
4.Fine-tuning
Như cũng đã nói ở bài trước, ta cũng nên lưu ý một điểu rằng, mặc định MySQL chỉ index những từ có độ dài tối thiểu là 4 ký tự.
Ví dụ những từ như “Y tá”, “Thư ký” sẽ không tìm ra vì ta thấy mặc dùng tổng độ dài của Y tá hay thư ký lơn hơn 4, nhưng ta đang nói tới từng từ một. Giả sử từ khóa “PHP developers” thì chữ PHP sẽ bị lượt bỏ không tìm kiếm vì độ dài bằng 3.
Muốn search những chữ có độ dài bé hơn 4 như vậy, chúng ta phải config MySQL (my.ini hay my.cnf) ft_min_word_len = 3 (hoặc thấp hơn, nếu muốn search các tiếng CJK thì phải set ft_min_word_len = 1).
Ngoài ra mặc định thì MySQL có một stopword list built-in, nếu như chúng ta không muốn dùng thì cũng có thể cấu hình lại ft_stopword_file ='path/to/your/file.txt'. File này chứa những từ chúng ta muốn lọc bỏ mỗi từ cách nhau bởi một ký tự xuống dòng.
Để những cấu hình này có hiệu lực, ta phải restart lại mysql và rebuild lại index bằng lệnh sau để thấy tác dụng:
REPAIR TABLE table_name QUICK;
(Option Quick có nghĩa là chỉ rebuild lại index mà không đụng tới data)