Tìm hiểu về Apache Solr
Sơ lược
Apache Solr là một open source full-text search platform dựa trên Apache Lucence. Lucene là một thư viện được viết bằng Java dùng để phân tích, đánh chỉ mục (indexing) và tìm kiếm thông tin được phát triển đầu tiên bởi Doug Cutting vào năm 2000. Cutting đồng thời cũng là tác giả của Hadoop lúc ông đang làm việc cho Yahoo vào năm 2005.
Apache Solr khởi đầu là một project nội bộ của CNET được tạo ra bởi Yonik Seeley, nhằm phục vụ chức năng tìm kiếm của website CNET vào nằm 2004 và được đóng góp cho Apache Software Foundation năm 2006. Solr không hoàn toàn là một RESTful interface của Lucene mà là sử dụng Lucene như là một component trong toàn bộ hệ thống. Sau phiên bản Solr 1.4, từ version 3.1 (tháng 3, 2011) thì Solr và Lucene dùng chung một codebase và version number.
Kiến trúc tổng quát
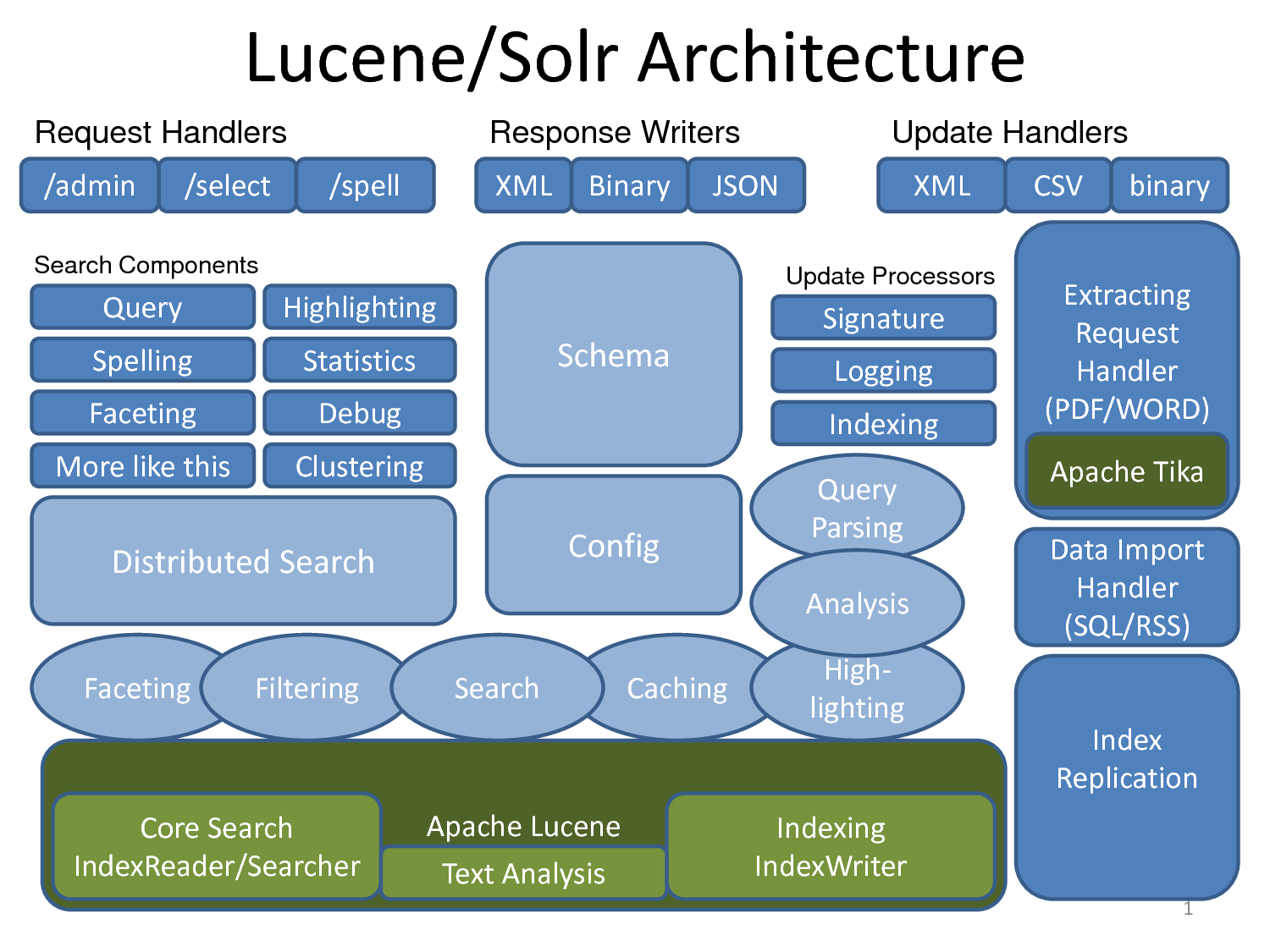
Tổng quát thì Solr bao gồm có nhiều thành phần (components) khác nhau bao gồm:
- Apache Lucene để phân tích, đánh chỉ mục tìm kiếm dữ liệu.
- Apache Tika dùng để trích xuất metadata, tìm kiếm và chỉ mục nhiều loại file document khác nhau như pdf, docx, mp3, jpg (hỗ trợ 66 file types khác nhau).
- Apache UIMA (đọc như you-eee-mah, Unstructured Information Managemen Architecture), đây cũng là một project thuộc Apache Foudnation, nó được dùng để phân tích một lượng lớn dữ liệu không có cấu trúc nhằm tìm ra được những thông tin có ích cho người dùng. Ví dụ:
- Phân tích các phim và trích xuất phụ đề rồi dựa vào đó để tìm ra diễn viên nào đóng trong phim đó.
- Tìm các bài viết, video, hình ảnh có liên quan tới chủ đề của một bài viết cụ thể nào đó.
- Apache Velocity là một Java-based template engine.
- Carrot2 (search results clustering engine) dùng để phân loại và nhóm các kết quả tìm kiếm thành những danh mục có cùng chủ đề (thematic categories).
Các chức năng nổi bật:
- Hỗ trợ cấu hình mềm dẻo (flexible configuration)
- Kiến trúc cho phép mở rộng (extensible architecture)
- Hỗ trợ nhiều ngôn ngữ (Multilingual)
Bằng việc hỗ trợ cấu hình dễ dàng các filter và tokenizer, nên Solr có thể giải quyết các vấn đề của các ngôn ngữ khác nhau. Về mặt kỹ thuật, thì chúng ta có thể xem thêm trang Analyzers, Tokenizer and Token Filters. và trang Language Analysis.
- Analyzer Analyzer đóng vai trò khảo sát các trường văn bản để tạo ra một token stream. Ví dụ:
WhitespaceAnalyzerxử lý phân tích văn bản thành những token dựa trên khoảng trắng. Analzyer được chỉ định như là một thuộc tính của của thẻ trong file cấu hình schema.xml. Ví dụ: “The quick brown fox jump over the lazy dog” sẽ được phân tích thành các tokens:[The] [quick] [brown] [fox] [jump] [over] [the] [lazy] [dog]
<fieldtype class="solr.TextField" name="nametext">
<analyzer class="org.apache.lucene.analysis.WhitespaceAnalyzer">
</analyzer>
</fieldtype>- Tokenizer Nếu như Analyzer tạo ra các token streams/input stream, thì Tokenizer chia nhỏ các stream đó thành những tokens (đơn vị nhỏ nhất để index, có thể là từ hay ký tự). Các ký tự trong input stream có thể bị bỏ qua như các ký tự không nhìn thấy được (whitespace như khoảng trắng, tab) hay các dấu phân cách (delimiter như dấu phẩy, dấu chấm).
Đối với các ngôn ngữ CJK (Trung-Nhật-Hàn) phải dùng tới N-Gram tokenizer. Tokenizer này sẽ tách input stream thành những token theo từng cụm có độ dài N tùy theo chúng ta cấu hình. Ví dụ với từ “bycicle” và N=4 –> N=5
<analyzer>
<tokenizer class="solr.NGramTokenizerFactory" minGramSize="4" maxGramSize="5"/>
</analyzer>thì chữ bycicle được phân tích thành các tokens như sau:
[bicy], [icyc], [cycl], [ycle], [bicyc], [icycl], [cycle]
Điều này có thể không có ý nghĩa với tiếng Anh nhưng với tiếng Trung-Nhật-Hàn thì nó rất có ý nghĩa. Bởi vì các ngôn ngữ này không các từ không cách nhau bởi khoảng trắng và sự kết hợp của một ký tự với ký tự đi trước hay sau nó cũng mang ý nghĩa khác nhau. Có thể lấy ví dụ như chữ đích (的), tùy theo kết hợp với các chữ khác mà nó mang ý nghĩa khác nhau. Ví dụ 目的 (mục đích), 的确 (đích xác), 是的 (đích thị), do tiếng Trung không phân cách bằng khoảng trắng cho nên việc index các tổ hợp có ý nghĩa rất quan trọng trong việc tìm kiếm.
<fieldType name="text" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
</analyzer>
</fieldType>- Filter
Giống như
Tokenizer,Filterlàm nhiệm vụ đọc input stream và tạo ra các token, nhưng dữ liệu đầu vào sẽ được xử lý thêm (ví dụ chuyển chữ hoa thành chữ thường, chuyển từ viết tắt (tên bang, tên thành phố) thành kiểu viết đầy đủ hoặc ngược lại).
<fieldType name="text" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory"/>
</analyzer>
</fieldType>Một số vấn đề liên quan tới ngôn ngữ khác:
-
Stopwors Stopwords là danh sách những từ vô nghĩa hoặc không giúp ích gì cho việc tìm kiếm và cần được loại bỏ khỏi index. Ví dụ trong tiếng Anh có các từ như:
an,and,at,as if,for,but,byv.v -
Stemming Stemming là việc giản lược các từ trở về dạng gốc của nó. Ví như trong tiếng anh
write,wrote,written,writingđều có gốc là write. -
Synonym Mỗi ngôn ngữ đều có một hệ thống từ đồng nghĩa và viết tắt riêng. Cho nên việc xử lý các vấn đề liên quan tới từ đồng nghĩa cũng rất quan trọng khi ta muốn mang lại kết quả tìm kiếm tốt nhất cho người dùng.
-
Protected words Solr hỗ trợ cấu hình loại bỏ các từ “bị cấm” khỏi index. Ví dụ đôi khi chúng ta cần loại bỏ tên người hay những từ khoá mang tính khiêu dâm đồi truỵ ra khỏi index chẳng hạn.
-
Compound word splitting Một số ngôn ngữ như tiếng Đức hay tiếng Phần Lan thường kết hợp các từ lại với nhau trở thành một từ mới mà không có khoản trắng ở giữa (ví dụ trong tiếng Phần thì bệnh viện của thành phố (city hospital) là
kaupunginsairaala: gồmkaupunginnghĩa làcủa thành phốvàsairaalalàbệnh viện, viết liền). -
Spelling checking Và rõ ràng là việc kiểm tra lỗi chính tả thì phụ thuộc chặt chẽ vào các ngôn ngữ khác nhau. Trong Solr 4.4.0 có 3 component implementations của SpellChecker:
org.apache.solr.spelling.IndexBasedSpellCheckerComponent này sẽ đưa ra các đề xuất dựa trên tần suất của các từ mà Solr đã index. Tức là dựa vào các từ cũ trong index để kiểm tra.org.apache.solr.spelling.FileBasedSpellCheckerBạn có thể chỉ định một file chứa các từ đúng, mỗi hàng một từ.org.apache.solr.spelling.DirectSolrSpellCheckerThay vì phải tạo ra n-gram index cho từ cần kiểm tra và thực hiện câu truy vấn so sánh với index có sẵn, thì component này sẽ sử dụng thuật toán Levenshtein để kiểm tra trực tiếp với index sẵn có. Xem thêm ở đây và ở đây
-
Facet navigation Xem thêm ở đây Faceted Search – the 120 Million Documents Story
-
Khả năng tuỳ chỉnh thứ tự xếp hạng của tài liệu (tunable scoring hay custom document ranking) Ứng dụng thực tế nhất của tính năng này có lẽ là quảng cáo (như sponsored search của Google) sửa dụng BoostQParserPlugin.
-
Khả năng mở rộng hệ thống (scalability)
-
Dễ tích hợp (Intergation) Do Solr được xây dựng dựa trên kiến trúc RESTful hỗ trợ kết quả trả về không chỉ ở dạng XML mà còn ở dưới dạng CSV hay JSON cho nên rất dễ dạng cho việc tích hợp với cách hệ thống sẵn có như Drupal và các ngôn ngữ và framework khác như Solr PHP client, Ruby on Rails (act_as_solr).
-
Sharding, Caching, Distributed search Solr hỗ trợ tìm kiếm phân tán trên các server khác nhau thông qua một tập hợp các tính năng được gọi là SolrCloud
-
Hỗ trợ Near real time search Tức là hỗ trợ index dữ liệu mới thêm vào gần như tức thời để có thể tìm kiếm.
Cấu trúc và Cài đặt
Để chạy thử Solr rất đơn giản, ta chỉ cần download Solr về giải nén và vào thư mục example chạy start.jar. Xem thêm tutorial của Solr 4.4.0 ở đây và tutorial về Solr ở đây.
Cấu trúc sau khi giải nén
.
|-- CHANGES.txt
|-- LICENSE.txt
|-- NOTICE.txt
|-- README.txt
|-- SYSTEM_REQUIREMENTS.txt
|-- contrib
|-- dist
|-- docs
|-- example
`-- licenses
$tar -xvf solr-4.4.0.tgz
$cd solr-4.4.0/example/
$java -jar start.jarSau đó truy cập vào địa chỉ http://localhost:8983/solr/, nếu thấy xuất hiện giao diện của Solr thì xem như bạn đã chạy Solr thành công trên máy của mình.
Ở trong Solr 4.4.0 thì file schema.xml và các file cấu hình của Solr nằm trong thư mục /solr-4.4.0/example/solr/collection1/conf
~/solr-4.4.0/example/solr/collection1/conf]$tree -L 1
.
|-- admin-extra.html
|-- admin-extra.menu-bottom.html
|-- admin-extra.menu-top.html
|-- currency.xml
|-- elevate.xml
|-- lang
|-- mapping-FoldToASCII.txt
|-- mapping-ISOLatin1Accent.txt
|-- protwords.txt
|-- schema.xml
|-- scripts.conf
|-- solrconfig.xml
|-- spellings.txt
|-- stopwords.txt
|-- synonyms.txt
|-- update-script.js
|-- velocity
`-- xsltVí dụ cấu hình một ứng dụng với Solr
Vì dụ sau đây sẽ cấu hình để Solr index và tìm kiếm dữ liệu từ database của mình. Giả sử ta có một database schema bookstore như sau:
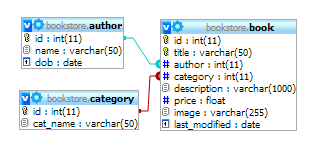
- schema.xml
Trong file schema này mình định nghĩa một fieldType là
text_viđể tìm kiếm tiếng Việt. Thực chất mình copy lại từ fieldType là text_en và thêm vàoASCIIFoldingFilterFactoryđể chuyển các ký tự unicode thành trở về thành các ký tự ASCII tương ứng. Hoặc chúng ta có thể dùng solr.MappingCharFilterFactory (xem thêm) và chỉ định file mapping tương tự cấu hình Sphinx.
<fieldType name="text_vi" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="English" protected="protwords.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true"
/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="English" protected="protwords.txt"/>
</analyzer>
</fieldType>
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true"/>
<field name="title" type="text_vi" indexed="true" stored="true"/>
<field name="author_name" type="text_vi" indexed="true" stored="true" />
<field name="category_name" type="text_vi" indexed="true" stored="true" />
<field name="description" type="text_vi" indexed="true" stored="true" />
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
</fields>- solrconfig.xml
Trong file solrconfig.xml chúng ta cấu hình để Solr có thể import data từ mysql để phục vụ cho việc indexing. Chúng ta phải thêm phần cấu hình trỏ tới thư viện dataimporthandler và mysql jdbc driver
<lib dir="../../../contrib/dataimporthandler/lib" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-dataimporthandler-\d.*\.jar" />
<lib dir="../../lib/" regex="mysql-connector-java-5.1.4-bin.jar"/>
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>- db-data-config.xml
File này sẽ định nghĩa các field sẽ được Solr index lấy từ bảng nào, trường nào trong database.
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/bookstore" user="root" password="" />
<document>
<entity name="book" query="SELECT id, title, author, category, description from book">
<field column="id" name="id" />
<field column="title" name="title" />
<field column="description" name="description" />
<entity name="category_name" query="SELECT cat_name FROM category c where c.id = '${book.category}'">
<field name="category_name" column="cat_name" />
</entity>
<entity name="author_name" query="SELECT name FROM author a where a.id = '${book.author}'">
<field name="author_name" column="name" />
</entity>
<field column="last_modified" name="last_modified"/>
</entity>
</document>
</dataConfig>- Sau khi cấu hình hoàn tất chúng ta tiến hành chạy Solr từ dòng lệnh
$java -jar start.jar
Bản chất là Solr chạy trên nền Jetty web server, nên khi thực tế deploy ta có thể deploy Solr trên một standalone Jetty server hay Tomcat server mà không cần thông qua start.jar.
Nếu trong quá trình start server mà chúng ta không thấy báo lỗi gì cả tức là việc cấu hình của chúng ta đã gần như thành công (ví dụ ClassNotFoundException hay Underfined field text)
Sau đó để tiến hành import data từ mysql ta mở trình duyệt và truy cập vào địa chỉ sau:
http://localhost:8983/solr/dataimport?command=full-import
Nếu mọi việc diễn ra suông sẻ chúng ta sẽ nhận được kết quả trả về như sau:
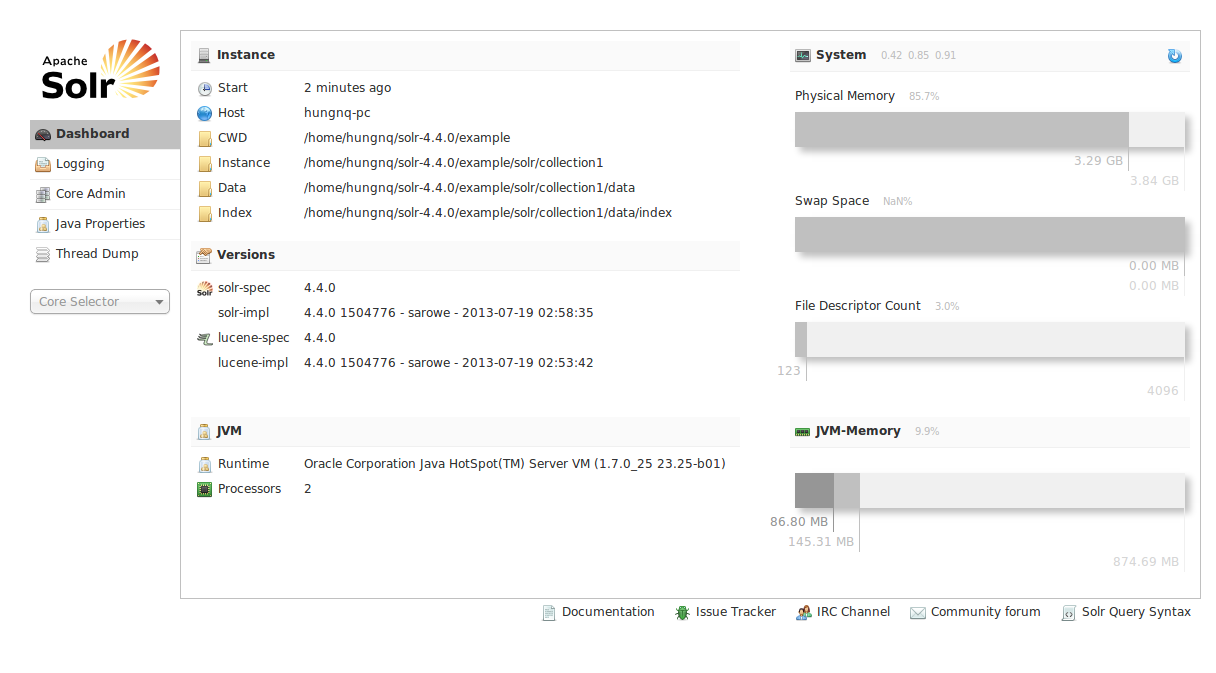
Sau đó để kiểm tra thử kết quả tìm kiếm của Solr chúng ta truy vấn thử một số lệnh như sau:
-
http://localhost:8983/solr/select?q=title:Harry+Potter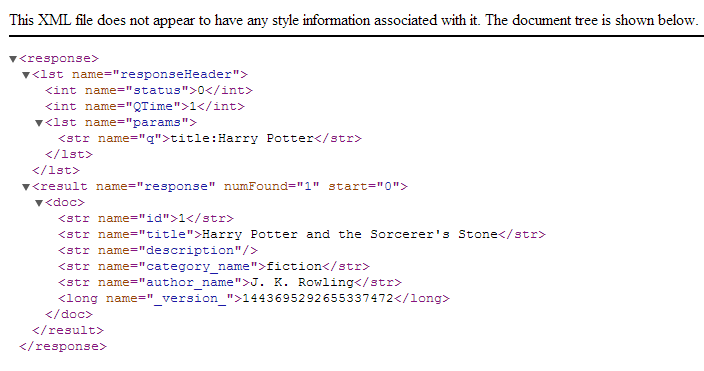
-
http://localhost:8983/solr/select?q=author_name:Nguyễn%20Nhật%20Ánh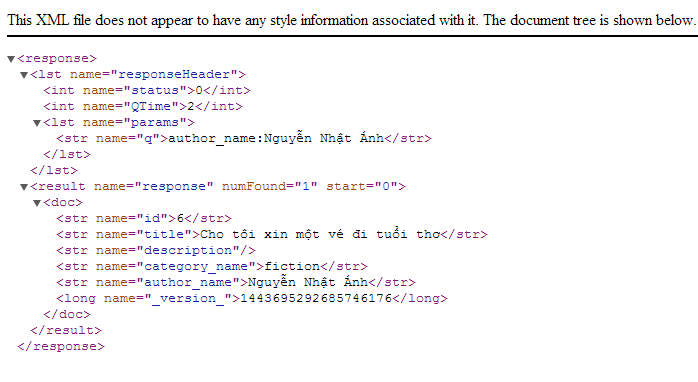
Để lấy lết kết quả trả về dạng json ta chỉ cần thêm tham số &wt=json vào sau câu truy vấn.
Ví dụ:
http://localhost:8983/solr/select?q=title:Harry+Potter&wt=json
Tới đây việc cấu hình và chạy thử Solr của chúng ta đã hoàn tất. Để tương tác với Solr thông qua PHP chúng ta có thể sử dụng thư viện solr-php-client. Hoặc chúng ta vẫn có thể tự implement một lớp để tương tác với kết quả xml hay json trả về từ Solr. Các file cấu hình ở thư mục /solr-4.4.0/example/solr/collection1/conf và database bookstore có thể tải về từ địa chỉ https://github.com/hungnq1989/solr-example
References:
- Apache Solr Reference Guid, n.d, 18 Aug 2013, <http://apache.mirrors.pair.com/lucene/solr/ref-guide/apache-solr-ref-guide-4.4.pdf>
- Jaran Nilsen, 2011, ‘Apache Solr Search for everyone’, 18 Aug 2013, <http://www.slideshare.net/jarannilsen/apache-solr-search-for-everyone>
- Peter Karussell, 2011, ‘Apache Solr: Get started, get excited’, 18 Aug 2013, <http://java.dzone.com/articles/apache-solr-get-started-get>
- Tyler Hams, 2012, ‘Searching with Solr’, 18 Aug 2013, <http://www.slideshare.net/blendinteractive/searching-with-sorl>
- ‘[Solr] CJKTokenizerFactory と NGramTokenizerFactory の動作の違い’, n.d, 18 Aug 2013, <http://d.hatena.ne.jp/knaka20blue/20090930/1254289965>
- Jason Hull, 2012, ‘Indexing Chinese Solr’, 18 Aug 2013, <http://java.dzone.com/articles/indexing-chinese-solr>