MySQL full-text search — part 3
Introduction
Following part 2, this post looks at how MySQL scores relevance and how full-text indexing fits into the picture.
1. High-level architecture
First, a quick picture of the full-text search pipeline. Details vary by engine; MySQL is one instance (for example, it does not ship a stemmer, so searching for the singular form will not automatically match plural forms).
A document typically goes through tokenization, optional stemming, stopword filtering, then indexing into on-disk index structures.
Tokenization splits the input into the smallest meaningful units—often words for English or Vietnamese (whitespace-delimited), or characters for CJK scripts where text may run without spaces between words.
Stemming maps word variants to a shared root. In English, jump, jumps, jumped, and jumping share the stem jump. (Again, MySQL’s built-in full-text path does not apply stemming the way Solr or Elasticsearch analyzers do.)
Stopwords are discarded as low-signal tokens—words that do little to discriminate documents for a given query. MySQL’s default list includes terms such as hello, welcome, were, it, us, and so on. See the manual for the full-text stopword list.
2. What is an index?
Roughly as Wikipedia puts it, an index is a data structure that speeds up reads at the cost of slower writes and extra storage. The same idea appears in print: the index at the back of a book lists where terms occur. Lucene in Action is a good example of a printed index page.

Search engines commonly rely on an inverted index: for each term, store which documents contain it.
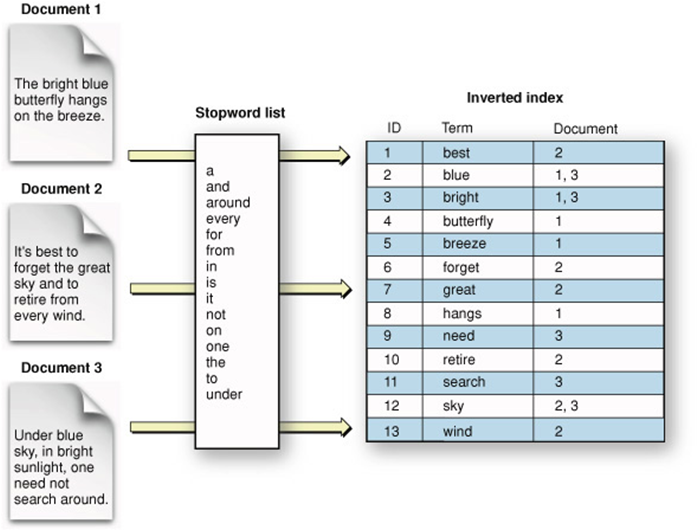
Like a book’s index, an inverted index records which documents contain which terms, so lookups avoid scanning every row—analogous to using an array index instead of iterating every element.
3. Relevance ranking
As in part 2, NATURAL LANGUAGE MODE sorts by relevance by default. The per-term contribution is often called weight (w). MyISAM’s classic model uses a form along the lines of:
w = (log(dtf)+1)/sumdtf * U/(1+0.0115*U) * log((N-nf)/nf)See the MySQL manual and internals write-ups (for example discussions of the MyISAM full-text algorithm) for exact definitions of dtf, sumdtf, U, N, and nf. Informally:
- The more often a term appears in one document, the more its weight can rise for that document.
- The more often it appears across many documents, the more its discriminative power drops—so very common terms are down-weighted.
So a term that shows up in almost every row can end up with a low or negative contribution in natural-language ranking—while BOOLEAN MODE still answers “does this row contain the token?” with a simple match (often treated as presence/absence unless you use boolean operators that adjust scores).
Take the keyword MySQL on the sample articles data from part 2. You can inspect stored full-text statistics with myisam_ftdump under MySQL’s bin directory: flags like c mean count; index 1 is the FULLTEXT(title, body) index and 0 is the id index (see the tool’s usage in the manual).
You may see MySQL scored below zero in the dump: it appears in every test row, so the global IDF-style factor punishes it. Other keywords that are not universal usually return at least one sensible hit in NATURAL LANGUAGE MODE. In BOOLEAN MODE, MySQL still matches rows because the engine is answering a binary “contains / does not contain” question unless you add ranking operators.
Boolean mode weights
Back in boolean mode, raw weights are often 0 or 1 (no match vs match). That changes when you use the boolean operators from part 2:
- Example: row 5 can score below 1 if it contains
YourSQLwhile the~operator marksYourSQLas a noise term—pulling the rank down. - If you promote
YourSQLwith>(e.g.>YourSQL), that row’s score increases.
So with ~, >, grouping, and similar operators, boolean scores are not limited to 0/1; you usually ORDER BY MATCH(...) AGAINST(...) to impose the order you want.
4. Fine-tuning
As in part 1, MySQL by default indexes only tokens whose length is at least ft_min_word_len (often 4 in older defaults).
Length is measured per token, not per phrase. Vietnamese examples such as Y tá or Thư ký can fail token-by-token even if the phrase is longer than four characters overall. For PHP developers, the token PHP has length 3, so it may be skipped until you lower the minimum.
To index shorter tokens, set in my.ini / my.cnf, for example:
ft_min_word_len = 3
For CJK-style tokenization strategies that need single-character terms, you may set ft_min_word_len = 1 (with the usual trade-offs).
MySQL also ships a built-in stopword list. To replace it, point ft_stopword_file to your own file (one term per line):
ft_stopword_file = 'path/to/your/file.txt'
After changing these settings, restart the server and rebuild full-text indexes—for MyISAM, a common pattern is:
REPAIR TABLE table_name QUICK;
QUICK rebuilds the index without rewriting all table data (see the manual for REPAIR TABLE and engine-specific rebuild steps for InnoDB full-text).
References
Official MySQL 8.0 Reference Manual entries and background material aligned with this post:
Chapters and modes
-
Full-text search — overview of
MATCH … AGAINST, supported indexes, and links to natural-language and boolean sections. -
Natural language full-text searches — default relevance ordering and how natural-language relevance is computed.
-
Boolean full-text searches — boolean operators (
+,-,~,>,*, etc.) and how they affect matching and ranking. -
Full-text stopwords — default stopword lists and how to customize them.
Configuration
ft_min_word_lenandft_stopword_file— minimum token length and custom stopword files. Related variables: search the manual’s server system variables page forft_.
Storage engines and maintenance
-
InnoDB full-text indexes — InnoDB full-text behavior; use this for index rebuild and optimization (not only MyISAM
REPAIR TABLE). -
myisam_ftdump— dump MyISAM full-text index entries for debugging (as in section 3). -
REPAIR TABLE— rebuild MyISAM indexes after changingft_*settings; see theQUICKoption and engine applicability.
General concepts
- Inverted index (Wikipedia) — textbook definition of the data structure behind typical full-text indexes (section 2).